
AI推理时代存储变局:铠侠"双引擎"战略重构数据中心架构
嘉宾专访 2026-04-02 10:05 电子工程专辑
当全球AI产业经历从"炼模型"到"用模型"的关键转折,一场关于存储架构的静默革命正在数据中心深处酝酿。数据中心NAND bit需求正在经历的爆发式增长。根据铠侠(KIOXIA)在近日举行的CFMS | MemoryS 2026峰会上展示的数据,2025年至2031年间,数据中心NAND bit需求年复合增长率(CAGR)将达到34%,其中AI推理需求的CAGR更是高达56%,远超AI训练(11%)和传统应用(14%)。
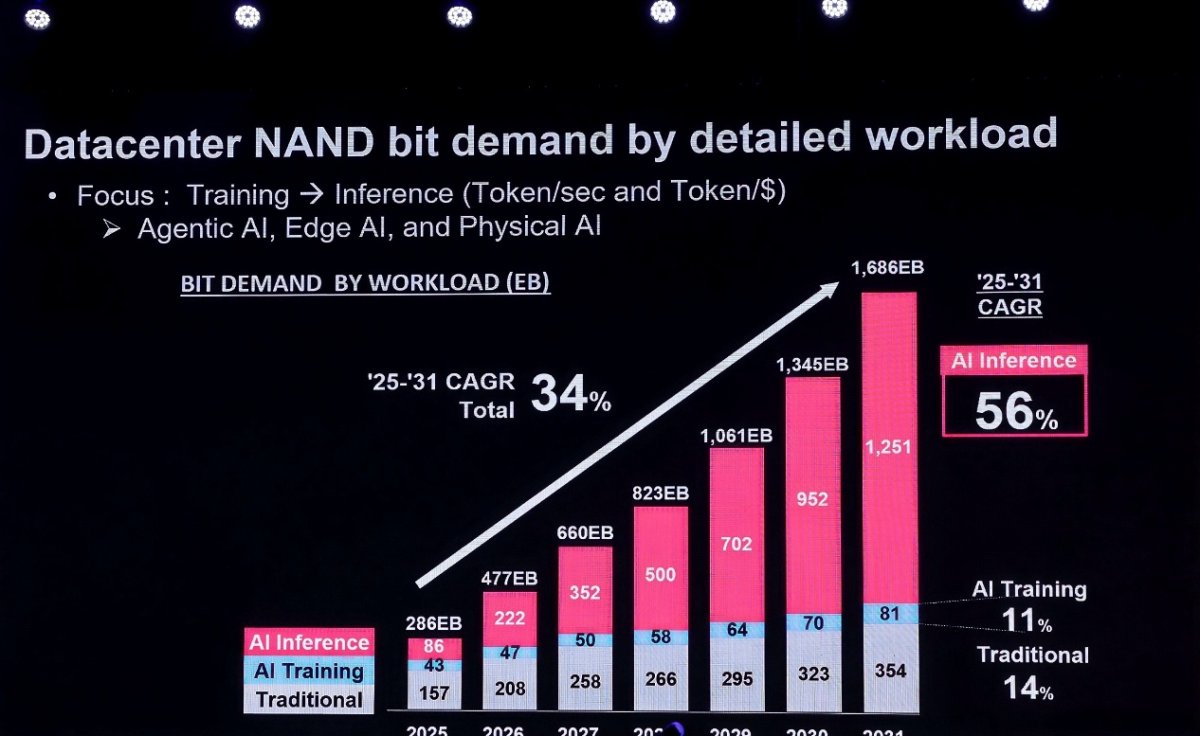
铠侠SSD首席技术执行官福田浩一在演讲中明确指出:"生成式AI的变革已经发生根本性的转变,从训练阶段建立大量的训练模型已经转换成推理模型。谁能提供最便宜、最快、最安全的推理AI,谁就能在这场变革中胜出,而存储已成为决定性的瓶颈。"

铠侠SSD首席技术执行官福田浩一
面对AI产业迅猛的需求结构转变,铠侠提出了SSD技术演进的四大关键方向:面向KV Cache扩展的高性能高容量方案、满足NVIDIA Storage-Next标准的超高IOPS方案、超大容量QLC方案,以及替代HDD的归档存储方案。
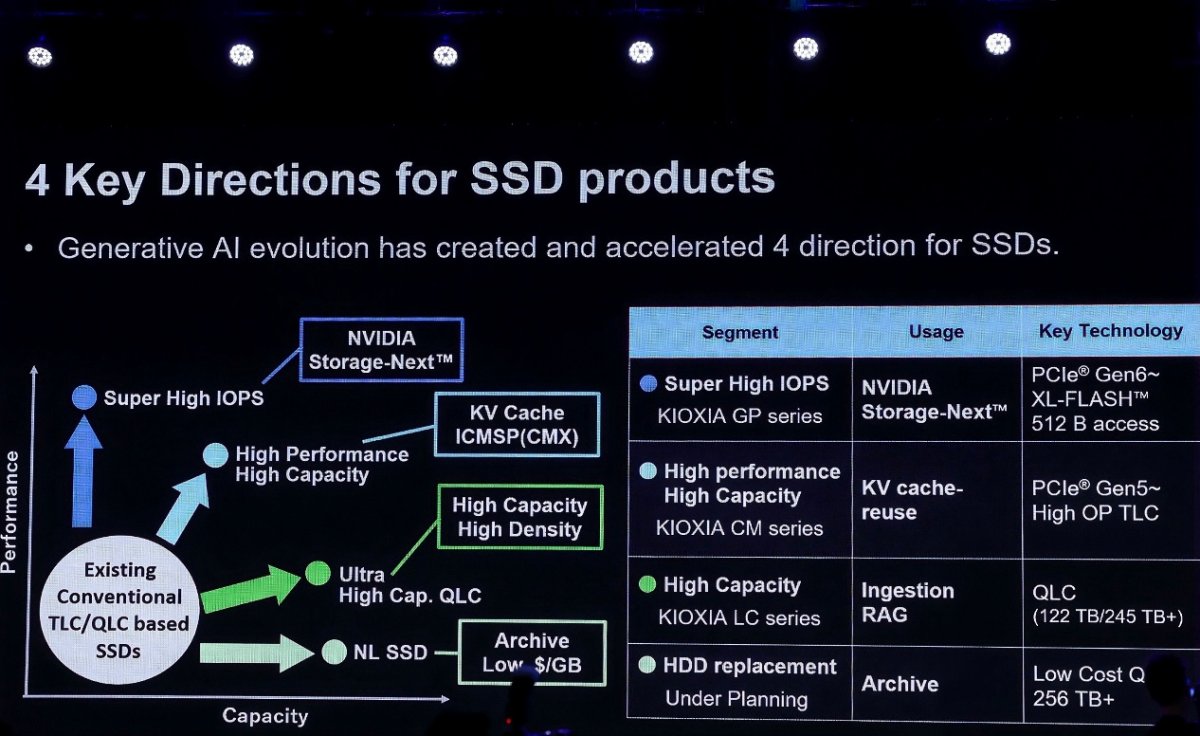
从HBM到SSD:KV Cache催生存储新层级
"随着问题数量的增长,对推理的数据需求不是线性增加,而是指数级增长。"福田浩一在演讲中强调了长上下文深度推理对存储架构的重构作用。在AI推理过程中,KV Cache(键值缓存)技术通过缓存中间计算结果避免重复计算,是优化推理速度、提升内存使用率的关键。然而,随着上下文长度的急剧增加,传统HBM和DRAM已无法容纳庞大的缓存数据,这迫使业界必须在存储架构中引入一个全新的层级——Context Memory Storage(上下文存储)。
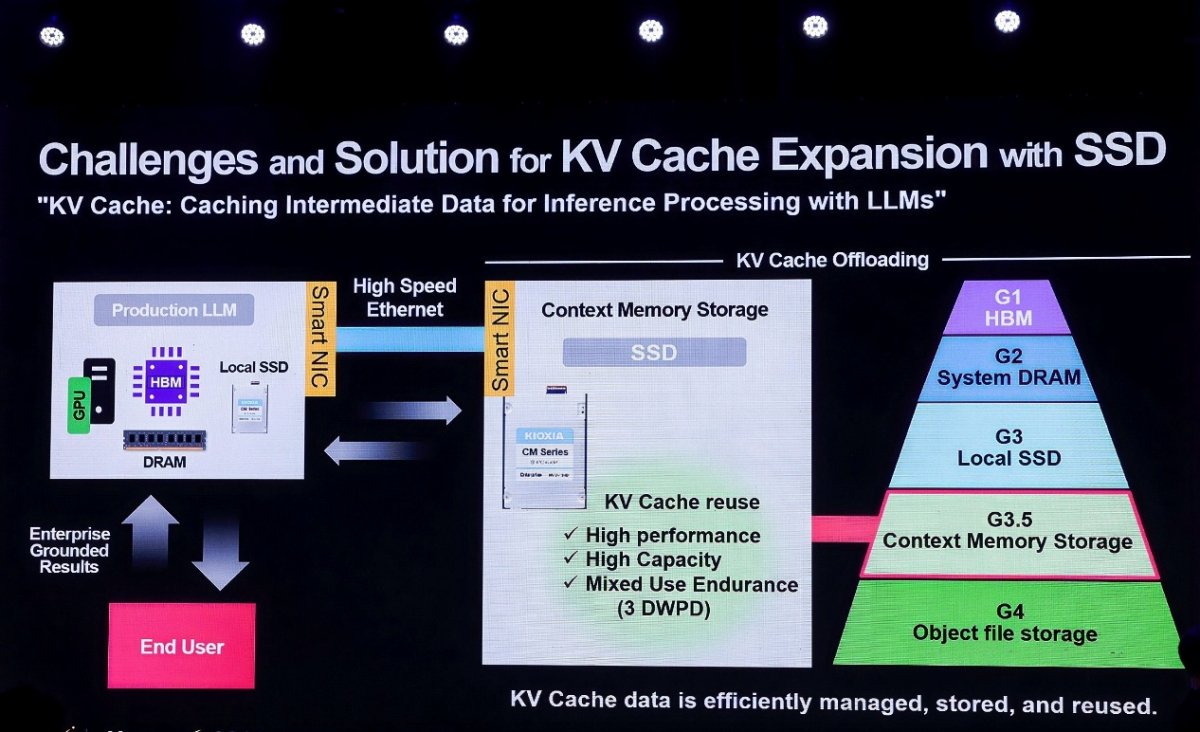
针对这一痛点,铠侠推出了专为KV Cache设计的CM9系列CMX版企业级SSD。该产品采用E3.S形态,容量高达25.6TB,具备3 DWPD(每日全盘写入次数)的混合使用耐久度,完美平衡了高性能、高容量与写入寿命的需求。在架构设计上,铠侠提出了"G3.5层"概念——介于本地SSD(G3)与对象文件存储(G4)之间的专用缓存层,通过高速以太网与Smart NIC连接,实现KV Cache数据的高效管理、存储与复用。

"长上下文的KV Cache会对SSD的需求产生进一步的促进,"铠侠高管在会后接受《电子工程专辑》采访时解释道,"原本KV Cache中的数据并不算特别庞大,通常存放在HBM或DRAM中。但随着数据量增大,这些内存已经不再适用,因此需要将部分数据存储到硬盘中。这不仅能节省GPU资源,更是避免电力和能量浪费的经济选择。"据悉,CM9系列CMX版将于今年第三季度正式上市,届时将为大规模推理环境提供关键的存储支撑。
BiCS FLASH Gen 9/10的双轴并进
在NAND闪存技术路线上,铠侠正采取独特的"双轴发展战略",摒弃了传统的单一代际替代逻辑。通过第九代与第十代BiCS FLASH的并行推进,铠侠试图在尖端性能与投资效率之间找到最佳平衡点。

第十代BiCS FLASH采用先进的CBA(CMOS直接键合到阵列)技术,实现了332层堆叠,相比第八代产品bit密度提升59%,在保持1 Tb TLC容量的同时,将接口速度提升至4.8 Gb/s(提升33%),读取吞吐量提升10%,写入吞吐量提升15%,数据传输能效提升超过15%。这一代产品主要面向对容量和性能有极致要求的高端应用。

与此同时,第九代BiCS FLASH则发挥CBA技术的灵活性优势,将现有的单元技术与最新的CMOS技术相结合,在成熟制程节点上实现高性能与低资本支出的平衡。"考虑到客户对产品不尽相同的需求,我们不会一概而论地认为容量越高就越好,"铠侠方面在接受采访时解释道,"针对不同的应用,我们可能会采用不同的技术,包括CMOS技术和功率技术,推出适应特定需求的产品。"
在移动端,面对端侧AI对存储带宽的迫切需求,铠侠宣布将于今年推出UFS 5.0产品。该产品拥有10.8GB/s的高速接口,有望解决当前手机运行AI时面临的存储带宽瓶颈,进一步推动设备端AI的发展。

AiSAQ:打破DRAM限制的向量检索革命
如果说KV Cache解决的是推理过程中的中间数据存储问题,那么铠侠的AiSAQ(All-in-Storage ANNS with Product Quantization)技术则瞄准了RAG(检索增强生成)场景下的大规模向量数据库难题。
"AI的数据量确实在持续增长,"铠侠高管在采访中指出,"RAG技术已经存在了一段时间,但在此之前,该技术主要基于DRAM实现,大量的数据存储在DRAM中,导致了数据堆积的问题。随着数据量的不断增长,原先存放在DRAM中的数据无法继续容纳。"

AiSAQ技术的核心在于采用"近零DRAM架构",通过独特的算法将所有数据结构保存在SSD上,仅保留最少的DRAM需求。这种架构不仅突破了DRAM容量的物理限制,实现了经济性的向量数据库扩展,更通过与NVIDIA cuVS库的深度结合,利用GPU加速索引构建,实现了惊人的性能突破。
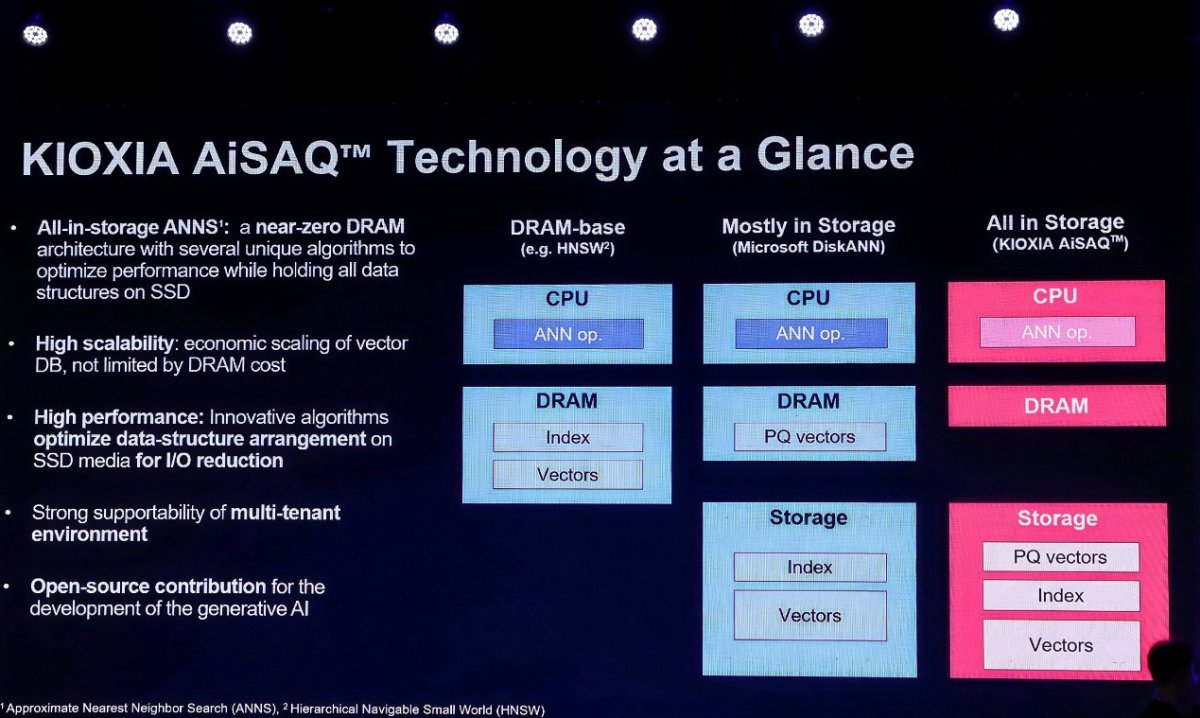
根据铠侠公布的最新数据,基于AiSAQ的解决方案在处理1024维向量时,索引构建速度相比传统CPU方案提升20.4倍(从28.4天缩短至1.4天),端到端数据摄取时间加速7.8倍(从31天缩短至4天)。目前,该技术已在48亿参数规模的向量检索场景中得到验证,并正向100亿参数规模迈进。

"AiSAQ技术既是可以提高人工智能答案准确性的技术,又是扩大SSD在生成式人工智能中应用的技术,"铠侠方面表示。这种开源贡献不仅刺激了SSD在AI应用中的使用,更可能从根本上改变传统存算架构的设计理念——从"以计算为中心"转向"以存储为中心",通过存储端的智能处理降低对昂贵DRAM的依赖。
QLC的进阶:从冷存储到温数据的主流化
在容量型存储领域,铠侠正推动QLC(四层单元)SSD突破传统的"低成本冷存储"定位,向温数据甚至部分热数据场景渗透。刚刚发布的LC9系列作为铠侠首款QLC NVMe企业级SSD,采用E3.L形态时容量可达245.76TB,2.5英寸与E3.S形态亦可达122.88TB,采用32层堆叠的BiCS FLASH第八代QLC 3D闪存。

"回顾两三年前,数据中心中QLC SSD的使用几乎不存在,"铠侠高管在采访中坦言,"但现今,QLC SSD正逐渐填补TLC SSD与近线HDD之间的空白。"
QLC SSD应用扩展的关键在于克服写入寿命的限制。铠侠通过FDP(Flexible Data Placement,灵活数据放置)技术,显著降低写放大因子(Write Amplification Factor,WAF),使其接近1,从而大幅延长SSD使用寿命。从TCO(总拥有成本)角度看,尽管QLC SSD的单品成本高于HDD,但在功耗、散热、空间占用等方面具有明显优势,特别适合需要频繁读取的温数据场景。
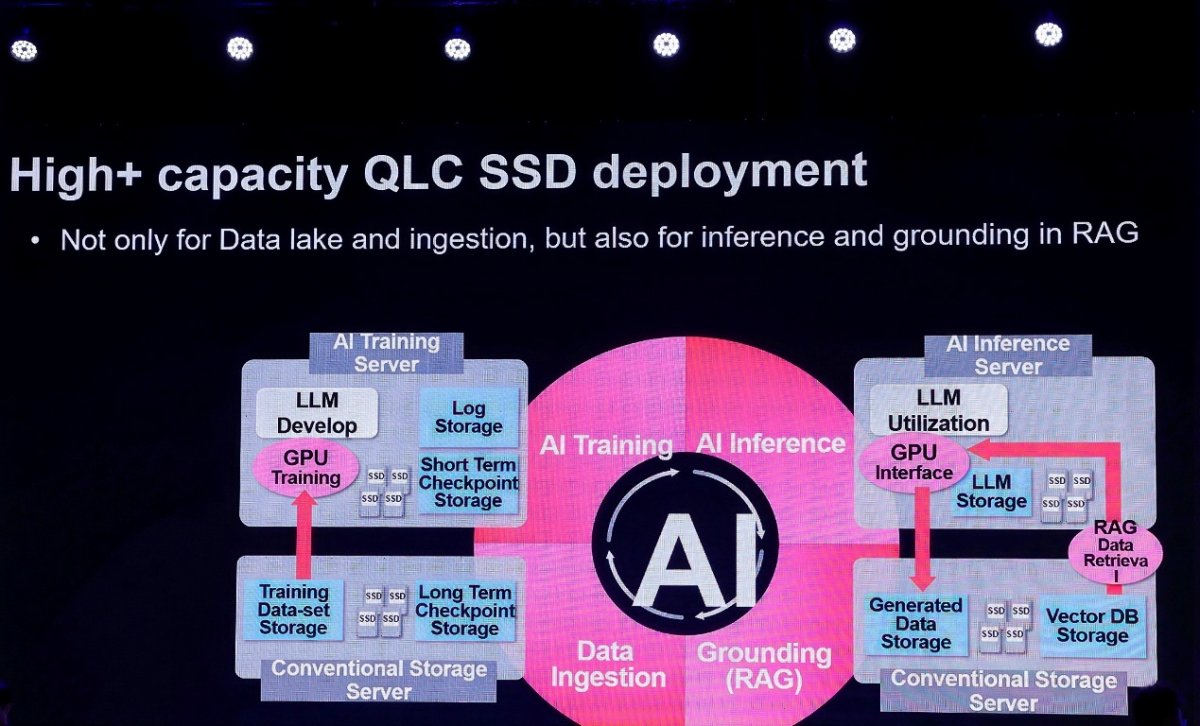
"与TLC相比,QLC的擦写次数较少,这是它的劣势,"铠侠方面解释道,"但利用FDP技术,可以显著降低WAF,这使得QLC SSD在数据中心中的使用可能会进一步增加。"目前,铠侠不仅在企业级市场推出QLC产品,在消费级市场也已有基于QLC的UFS产品批量生产并投入市场。
供需紧平衡:AI驱动下的存储新常态
面对当前企业级存储市场的供需紧张与价格上涨,铠侠展现出了审慎而乐观的态度。"由于对人工智能和数据中心的需求大幅增加,预计在可预见的未来,供需形势仍将非常紧张,"铠侠高管在采访中的表态与行业观察不谋而合。对于市场关于"2027年扩产落地后是否会有迅速回调风险"的担忧,铠侠方面认为,鉴于AI普及的持续性,"预计在可预见的未来需求不会急剧下降"。
在供应策略上,铠侠强调不会将重心放在单一应用领域,而是采取整体平衡的策略。"铠侠不会将重点放在一个极端的应用上,"公司方面表示,"而是在生产和销售产品时考虑到整体平衡,关注每种应用的需求趋势。"这种策略既体现在企业级与消费级市场的平衡,也体现在不同技术路线(如TLC与QLC)的产能配置。
"今后将采取双轴发展战略,"铠侠总结道,"满足尖端应用的高级需求保持最佳投资效率的同时,开发并向市场推出具有竞争力的产品。"通过第十代BiCS FLASH的高密度路线与第九代的高性价比路线并行,铠侠试图在AI带来的存储变局中,既抓住高性能计算的市场机遇,又满足数据中心大规模部署的成本诉求。
当AI推理成为新的增长引擎,当存储从"配角"升级为决定AI系统效率的关键瓶颈,铠侠通过"双引擎"战略构建的技术与产品矩阵,正试图重新定义闪存在智能时代的角色。正如福田浩一在演讲结尾所言:"作为行业创新者,铠侠将持续推进闪存的边界,释放更多可能性。"在这场由AI驱动的存储革命中,如何平衡性能、容量与成本,如何在DRAM之外开辟新的存储层级,将成为决定未来数据中心架构走向的关键命题。