
PCIe 7.0时代来临:Cadence全栈IP如何破解AI Factory数据互连瓶颈?
嘉宾专访 2026-04-02 14:51 电子工程专辑
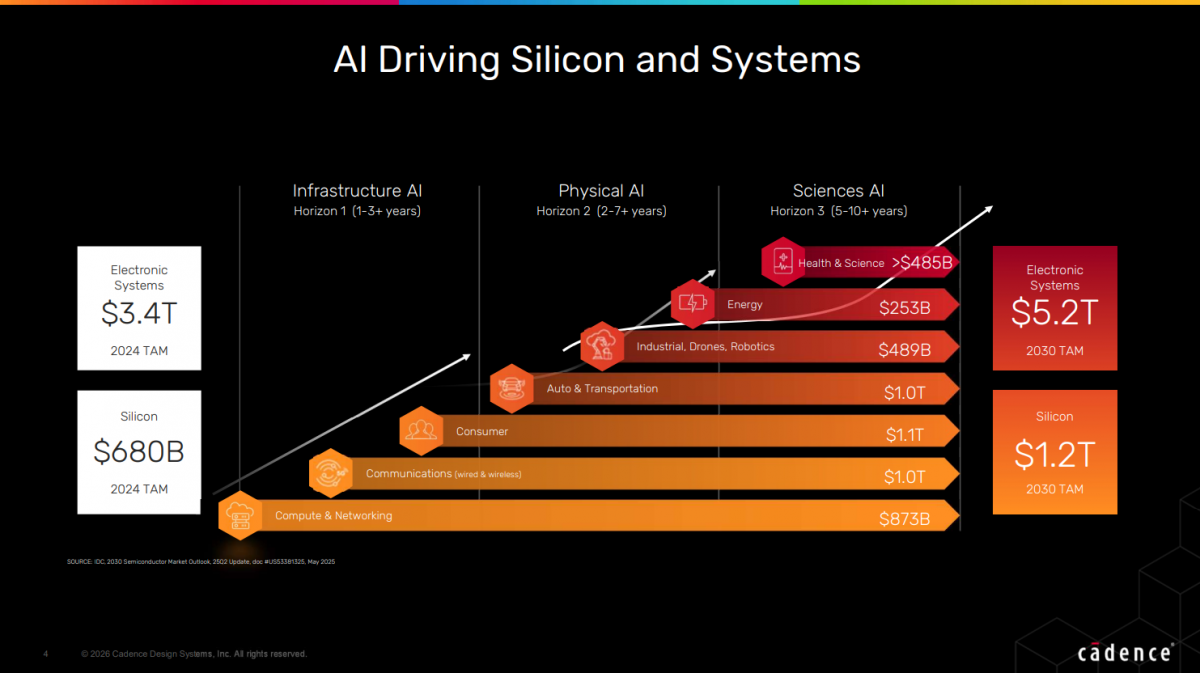
当全球AI基础设施从千卡集群向十万卡规模跃迁,当HPC(高性能计算)芯片在台积电营收占比连续六个季度持续攀升并占据主导,半导体行业正面临一个根本性转变:算力扩张的瓶颈已从晶体管密度转向数据流动效率。IDC预测,到2030年全球电子系统市场规模将从2024年的3.4万亿美元激增至5.2万亿美元,半导体市场从6800亿美元跃升至1.2万亿美元。在这波AI驱动的半导体复兴浪潮中,"Designing for data movement is key"(设计数据流动是关键)已成为架构师们的行业共识。
在近日举行的CFMS | MemoryS 2026峰会现场,这种焦虑与机遇交织的技术变革氛围尤为明显。从HBM4e到UCIe 64G,从PCIe 7.0到CXL 3.2,存储、接口与芯粒互联三大创新方向正在重构AI Factory的底层架构。

Cadence公司亚太区IP与生态系统销售群资深总监陈会馨(Wendy Chen)在接受《电子工程专辑》专访时指出:"如果大家关注上周的GTC峰会,会发现GPU全球领头羊公司英伟达已经开始布局PCIe 7.0生态系统。实际上,随着AI计算的激增,存储带宽已成为新的瓶颈,其需求正在迅速翻倍增长。"

Cadence公司亚太区IP与生态系统销售群资深总监陈会馨(Wendy Chen)
PCIe为何成为AI互连的通用基石?
在AI工厂架构中,互联技术承担着三大核心功能:主机与加速器(CPU-GPU/XPU)互连、网络接口卡(NIC)连接、以及NVMe SSD存储接口。面对带宽与延迟的双重挑战,为何PCIe能在众多协议中脱颖而出?
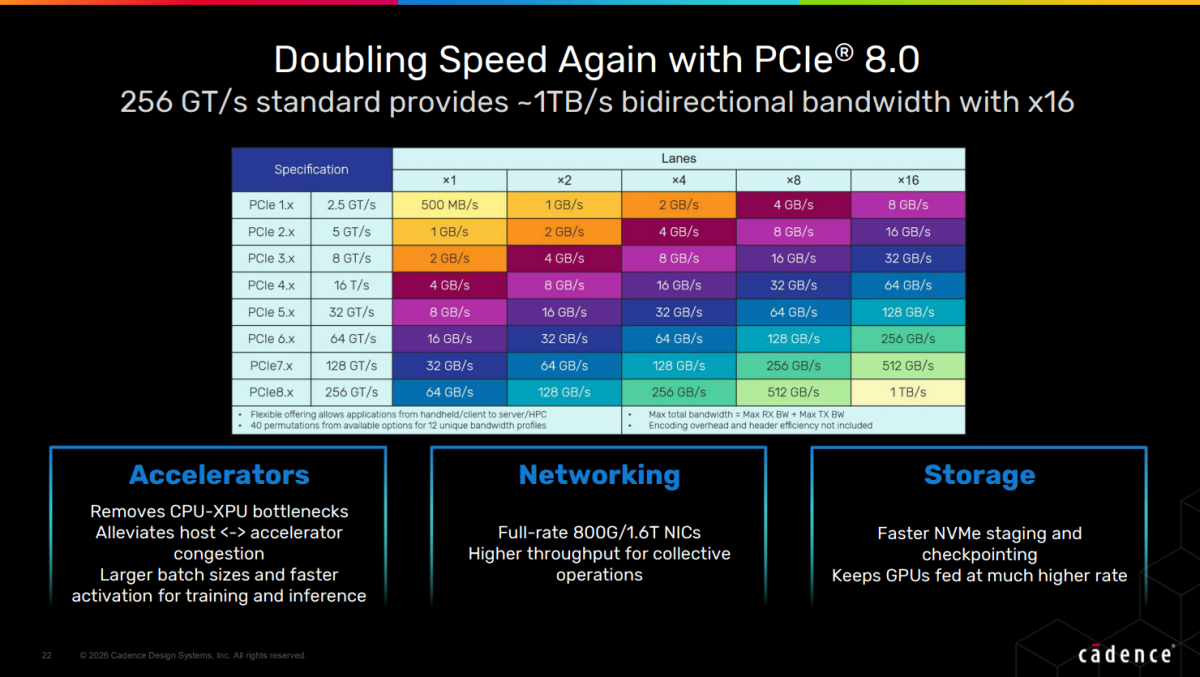
陈会馨详细解析了PCIe作为主机互连的技术价值:"AI工作负载对互联提出几个关键要求:带宽的可扩展性、很低的同步延迟、原生的P2P(点对点)能力、大规模并行队列和原子操作,以及灵活的拓扑性、可靠性、安全性和虚拟化能力。"从规格演进看,PCIe正经历代际跃迁——PCIe 6.0率先采用PAM4信号调制和轻量级FEC(前向纠错),将单lane速率提升至64GT/s;PCIe 7.0在此基础上翻倍至128GT/s;而预计2026年推出0.5版本、明年升级1.0版本的PCIe 8.0标准将达到256GT/s,实现x16配置下约1TB/s的双向带宽。

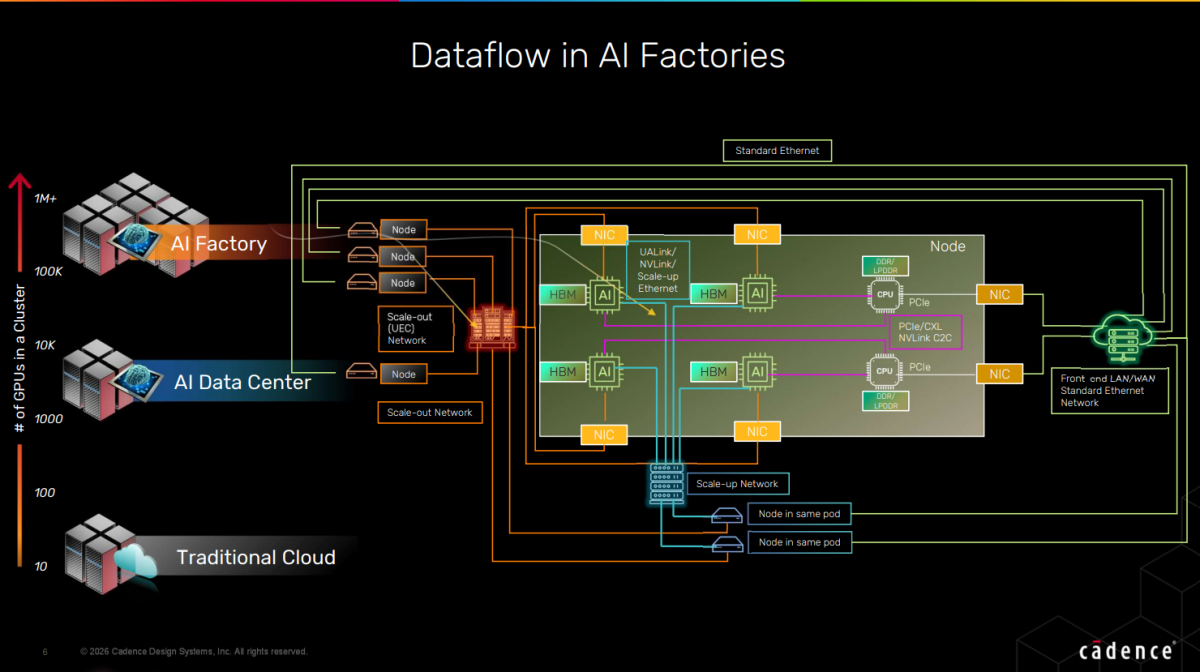
"AI工厂最大的瓶颈在于如何解决互联集群的技术问题,"陈会馨强调,"是否可以在同一机柜内集成更多的GPU,如何扩展到更多的机柜,并解决低延迟和数据传输的问题,这些都是新的挑战。"特别是在AI训练场景下,PCIe SSD承担了训练数据暂存、大模型状态权重参数保存(Checkpoint)、特征缓存和高速暂存区等关键任务,"与传统存储不同,AI场景对SSD要求更加严苛,需要极高的带宽和耐受力,必须长时间承受很重的持续工作负载,而不仅是追求峰值性能。"
Cadence全栈IP解决方案剖析
面对PCIe技术的快速迭代与复杂验证挑战,Cadence已构建起覆盖物理层到软件层的完整IP解决方案,并在先进工艺节点实现突破。
在PCIe 6.0领域,Cadence推出的解决方案实现了<280mW的active lane功耗,具备充足的SRIS(Separate Refclk Independent SSC)模式JTOL(Jitter Tolerance)裕量,并支持双模控制器。该方案兼容PCIe 6.3、CXL 3.2和Ethernet 56G,已在台积电5nm、3nm及三星工艺节点完成硅验证。

更令人瞩目的是PCIe 7.0的进展。Cadence在峰会期间展示了经过台积电验证的PCIe 7.0 IP,支持128GT/s速率,BER(误码率)性能超过规格要求100倍以上,同样具备充足的JTOL裕量。"PCIe 7.0与6.0产品性能非常一致,其实就是速率上的翻倍,"陈会馨解释道,"Cadence在PCIe 8.0的IP研发上从去年年底就开始了,这并非从0到1的设计,而是基于PCIe 7.0的技术积累。"

在架构层面,Cadence控制器IP采用可扩展设计,支持1至16 lanes和256 PF/VFs,原生支持SR-IOV、IDE(Integrity and Data Encryption)等关键特性。特别值得一提的是,Cadence是业界唯一提供多通道子系统测试芯片(Test Chip)的IP供应商。陈会馨强调:"我们的验证不是仅验证物理层,还验证协议层,并且是多个lane。你可以拿到我们的测试板,在真正的环境里和仪器厂商甚至你自己的主板进行互联测试,这大大降低了客户设计SoC的风险。"这种子系统测试方法论结合了软件仿真(Xcelium PCIe VIP)和硬件加速(Palladium PCIe Accelerated VIP),通过"降速桥"配件实现接近真实硅片的系统级验证。

在生态合作方面,Cadence正与Arm Neoverse平台深度协同。"ARM现在在做CPU的子系统,称为ARM CSS(Compute Subsystem),"陈会馨介绍,"楷登电子必须把IP放在真正跟客户SoC设计相似的验证环境中。"双方合作已在实际项目中落地,采用PCIe 6.0子系统并兼容CXL 3.2。关于CXL与PCIe的融合,她指出:"PCIe和CXL的底层物理层是相同的,但在协议层存在差异。CXL的主要应用场景是将整个系统的内存整合为一个大的内存池,使CPU、GPU和XPU都可以访问,从而更有效地管理和使用内存。"
迈向256GT/s与AI驱动设计未来
展望未来,PCIe 8.0将在2027年左右到来,其256GT/s的速率将带来1TB/s的双向带宽,这将彻底解决AI训练中的Checkpoint存储瓶颈,支持更大规模的训练数据暂存,实现"让GPU持续处于计算饱和状态"的理想目标。
"从IP设计角度看,先进工艺带来诸多优势,"陈会馨分析道,"PCIe已从纯模拟技术发展为数字化和模拟混合架构,特别是应用了DSP技术。工艺越先进,DSP运行速度越快,从而支持更高的速率。"她同时强调,Cadence正将其EDA工具中的AI能力延伸至IP设计,"目前Cadence的EDA技术正从内嵌AI到AI Agent整套方案去发展,这也会影响我们的IP设计。"
当AI集群从千卡走向十万卡,当算力扩张遭遇数据搬运的物理极限,PCIe技术的每一次代际跃升都在重新定义基础设施的边界。Cadence通过其全栈IP解决方案——从<280mW的低功耗PHY到>100x BER性能的高可靠性设计,从多通道子系统测试到与Arm生态的深度协同——正在为AI工厂构建起稳定、高效、可扩展的互联底座。随着PCIe 8.0时代的临近,这场关于数据流动的技术革命,才刚刚开始。