编辑: 发布:2021-10-25 16:19

受新冠肺炎疫情影响,全球数字化转型进程加快,存储器半导体技术的演变模式也随之发生改变。人工智能(AI, Artificial Intelligence)、物联网(IoT, Internet of Things)和大数据等技术正迅速发展,并广泛应用于远程办公、视频会议和在线课堂中,导致待处理的数据量激增。根据2017年国际数据公司(IDC, International Data Corporation)发布的《数据时代2025》研究报告(见图1),到2025年,全球数据量将达到163泽字节(zettabytes)1,其中有5.2泽字节(zettabytes)需进行数据分析。
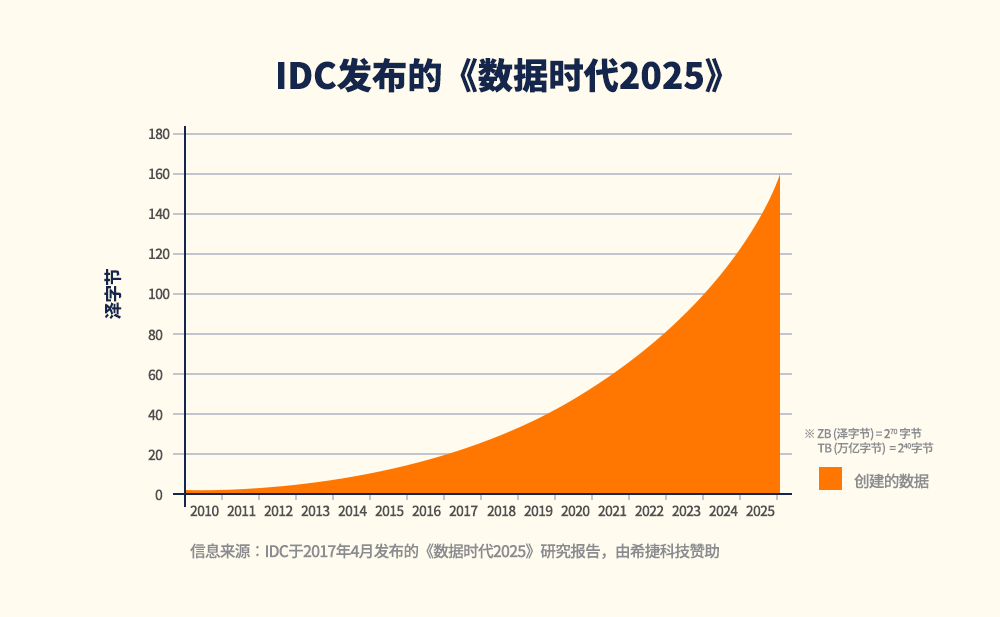
图1:IDC发布的《数据时代2025》
当前的计算机系统采用冯·诺伊曼(Von Neumann)体系结构2。根据图2所示的内存层次结构,当中央处理器(CPU)处理来自片外主内存(DRAM)的数据时,常用数据会被存储在快速且高能效的缓存(L1、L2、L3)中,以提高性能和能效。但是,在处理大量数据的应用中,大部分数据需从主内存中读取,因为待处理的数据规模非常大,超出了缓存的存储规模。
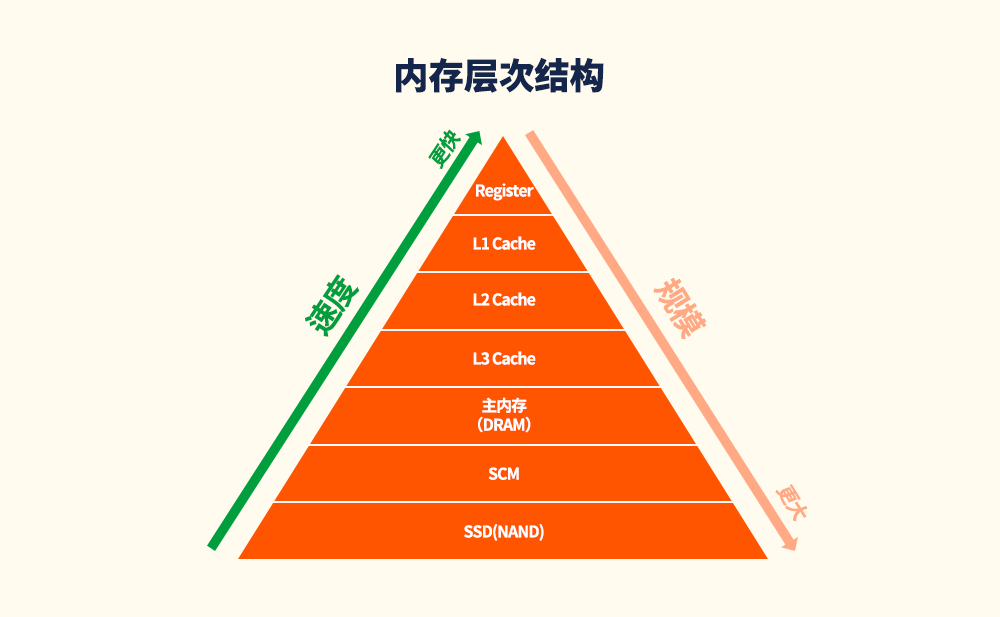
图2:内存层次结构
在这种情况下,CPU和主内存之间的内存通道带宽成为性能瓶颈3,并且在CPU和主内存之间传输数据需要消耗大量能量。要突破这一瓶颈,需要扩展CPU和主内存之间的通道带宽,但是若当前CPU的针脚数量已经达到极限,带宽的进一步改进便将面临技术方面的难题。在数据存储和数据计算分离的现代计算机结构中,此类内存墙问题的出现是不可避免的。
假设处理器进行乘法运算的功耗约为1,将数据从DRAM提取到处理器所消耗的能量是实际运算所需能量的650倍,这表明最大限度地减少数据传输量对于性能和能效的改进非常重要。(图3)
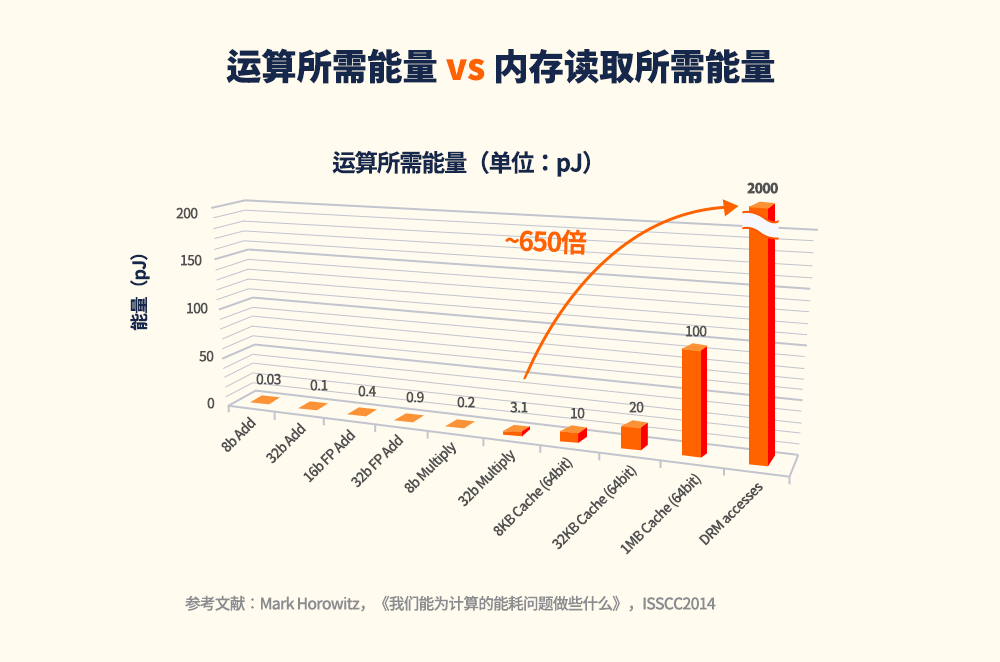
图3:运算所需能量与内存读取所需能量对比
深度神经网络(DNN, Deep Neural Network)4是机器学习(ML, Machine Learning)的一种,其中最具代表性的是应用于计算机视觉(CV, Computer Vision)的卷积神经网络(CNN, Convolutional Neural Networks)和应用于自然语言处理(NLP, Natural Language Processing)的递归神经网络(RNN, Recurrent Neural Networks)。近来,推荐模型(RM, Recommendation Model)等新应用也倾向于采取DNN技术。其中,递归神经网络主要用于进行矩阵向量乘法运算。递归神经网络具有数据重用量低的特点,内存读取次数越多,通过内存通道传输的数据就越多,这也成为提高性能的瓶颈。
为了突破性能瓶颈,业界正在重新审视应用内存中处理(PIM, Processing In Memory)5概念的DRAM。从定义可以看出,PIM技术指直接在内存中处理数据,而不是把数据从内存读取到CPU中再进行处理。这样可以最大限度地减少数据传输量,帮助克服上述瓶颈。从20世纪90年代末到21世纪初,学术界一直在积极研究这一概念,但由于DRAM工艺和逻辑工艺存在技术上的难点,且若以DRAM为载体在内存中实现CPU的功能,成本会相应增加,这导致PIM技术不具备竞争优势,因此迟迟未能进入商业化阶段。然而,PIM需求的日益增长以及工艺技术的进步重新唤起了实施PIM的可能性。
要想理解PIM,必须先了解人工智能的需求。图4给出了神经网络的全连接(FC, Fully Connected)层6示例。左图中,输出神经元y1与输入神经元x1、x2、x3和x4相连,并且各个连接的突触权重分别为w11、w12、w13和w14。在处理全连接层的过程中,人工智能运算单元将各个输入神经元的权重相乘,再将各项乘积相加,然后应用如线性整流函数(ReLU, Rectified Linear Unit)等激活函数7。概括而言,如右图所示,如果存在多个输入神经元(x1,x2,x3,x4)和输出神经元(y1,y2,y3),人工智能计算单元会将各个输入神经元的连接权重相乘,再将乘积相加。事实上,这些运算可以被视为矩阵的乘法和加法运算,因为输入神经元被等量使用。
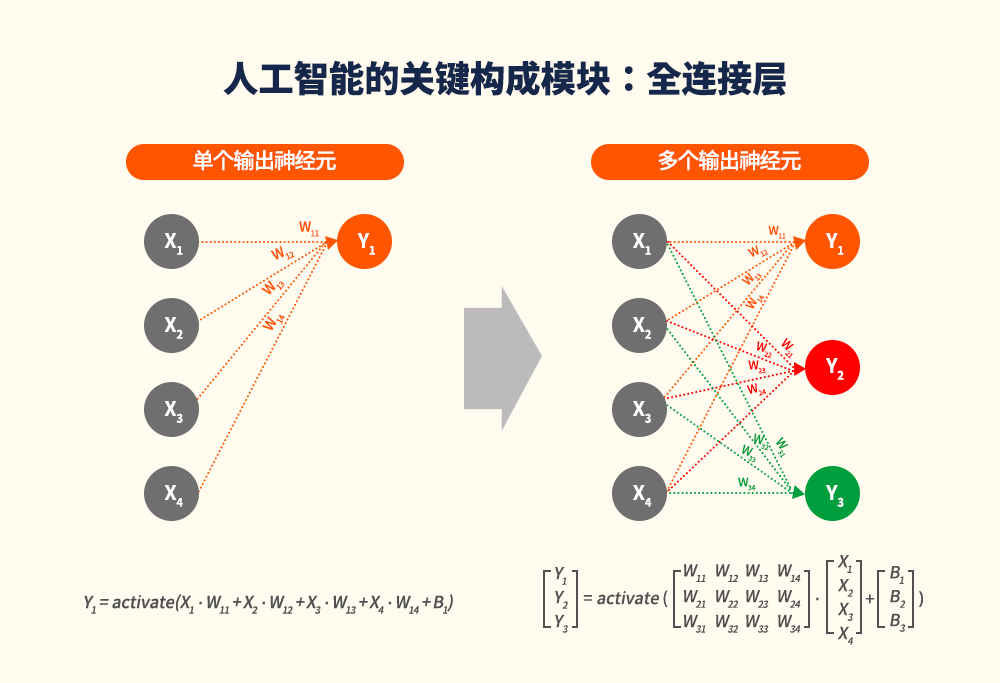
图4:人工智能的关键构成模块:全连接层(示例)
如图5所示,如果内存中可以加入这些运算回路,则无需再将数据传输到处理器中处理,只需将结果传送到处理器即可。这样可以显著减少高能耗的数据传输操作,从而提高复杂运算的能源效率。基于这样的应用理念,SK海力士正在开发PIM DRAM。对于递归神经网络等内存受限型应用,如果可以在DRAM中加入运算回路,则有望显著提高性能和能效。鉴于需要处理的数据量将继续大幅增加,PIM有望成为提高当前计算机系统性能限度的有力选择。
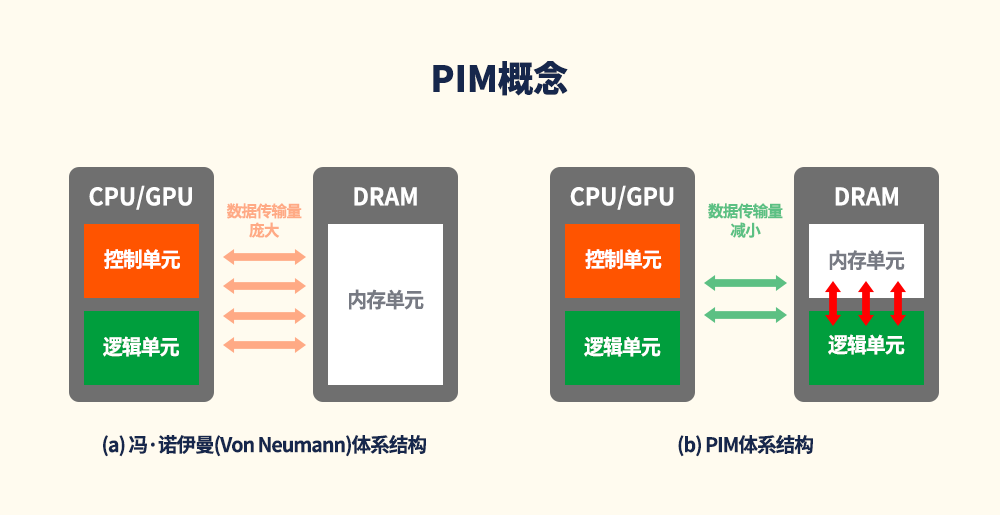
图5:PIM概念
参考来源
1 泽字节:等于1021字节。
2 冯·诺伊曼体系结构:使用CPU和存储装置来驱动计算机。
3 性能瓶颈:这一性能瓶颈也称为冯·诺伊曼瓶颈,即,由于处理器在读取内存过程中处于空闲状态,计算机系统的吞吐量会受处理器的限制。
4 深度神经网络(DNN, Deep Neural Network):输入层和输出层之间的多层人工神经网络(ANN, Artificial Neural Network)。神经网络种类多样,但均由相同的部分构成:神经元、突触、权重、偏置和函数。
5 内存中处理(PIM,有时称为存内计算):将处理器与RAM(随机存取存储器)集成在单个芯片上。集成后的芯片也被称为PIM芯片。
6 全连接层:每一层的任意一个神经元均与其前一层的所有神经元相连接。现行大多数机器学习模型中,最后几层都是全连接层,全连接层会编译前几层提取的数据并进行最终输出。
7 神经网络中的激活函数:用于定义如何将输入神经元的加权和映射到网络某一层中一个或多个节点的输出端。线性整流激活函数(ReLU, Rectified Linear Unit)是一个分段线性函数,它把所有的负值都变为0,而正值不变。

| 存储原厂 |
| 三星电子 | 53900 | KRW | +1.70% |
| SK海力士 | 172500 | KRW | +2.38% |
| 铠侠 | 1646 | JPY | -3.46% |
| 美光科技 | 90.120 | USD | +3.48% |
| 西部数据 | 60.240 | USD | +1.04% |
| 南亚科 | 31.30 | TWD | +2.96% |
| 华邦电子 | 15.35 | TWD | +2.33% |
| 主控厂商 |
| 群联电子 | 478.0 | TWD | +3.02% |
| 慧荣科技 | 53.900 | USD | +1.26% |
| 联芸科技 | 44.16 | CNY | +3.06% |
| 点序 | 46.00 | TWD | +2.22% |
| 国科微 | 73.93 | CNY | +0.41% |
| 品牌/模组 |
| 江波龙 | 94.21 | CNY | -1.10% |
| 希捷科技 | 87.310 | USD | -0.26% |
| 宜鼎国际 | 214.5 | TWD | +1.90% |
| 创见资讯 | 90.9 | TWD | +2.13% |
| 威刚科技 | 79.2 | TWD | +0.38% |
| 世迈科技 | 18.510 | USD | +0.82% |
| 朗科科技 | 22.35 | CNY | -2.10% |
| 佰维存储 | 67.40 | CNY | -0.35% |
| 德明利 | 93.30 | CNY | +0.97% |
| 大为股份 | 12.71 | CNY | -2.83% |
| 封测厂商 |
| 华泰电子 | 34.45 | TWD | +1.32% |
| 力成 | 123.0 | TWD | +1.23% |
| 长电科技 | 39.73 | CNY | -0.63% |
| 日月光 | 161.5 | TWD | +2.54% |
| 通富微电 | 29.76 | CNY | -1.39% |
| 华天科技 | 12.19 | CNY | -0.08% |
深圳市闪存市场资讯有限公司 客服邮箱:Service@ChinaFlashMarket.com
CFM闪存市场(ChinaFlashMarket) 版权所有 Copyright©2008-2023 粤ICP备08133127号-2


